Los mayores beneficios de los hilos provienen de las
consecuencias del rendimiento:
- Lleva mucho menos tiempo crear un hilo en un proceso existente, que crear un proceso totalmente nuevo.
- La creación de un hilo puede ser hasta 10 veces más rápida que la creación de un proceso en Unix.
- Lleva menos tiempo finalizar un hilo que un proceso.
Modelos
Hilos a nivel de usuario.
- El kernel probablemente desconozca la existencia de los hilos.
- Como no se involucra al kernel, las operaciones sobre los hilos son más rápidas.
Hilos a nivel de kernel
El núcleo gestiona los hilos. No hay código de gestión de hilos en la aplicación, sólo la
interfaz (API) para acceder a las utilidadesde los KLT.
FORMAS DE MULTIHILOS
Multihilo apropiativo
Permite al sistema operativo determinar cuándo debe haber un cambio de contexto. La desventaja de esto es que el sistema puede hacer un cambio de contexto en un momento inadecuado, causando un fenómeno conocido como inversión de prioridades y otros problemas.
Multihilo cooperativo
Depende del mismo hilo abandonar el control cuando llega a un punto de detención, lo cual puede traer problemas cuando el hilo espera la disponibilidad de un recurso.
Modelos Multihilo
En este tipo de modelo se asigna un hilo de usuario a un hilo de núcleo. Es decir, cada hilo de ejecución es un único proceso con su propio espacio de direcciones y recursos.
Este enfoque de modelo asigna múltiples hilos de nivel de usuario a un hilo de nivel de núcleo. La administración concerniente de los hilos se lleva a cabo mediante la biblioteca de hilos en el espacio de usuario.
La migración de un entorno de proceso a otro se lleva a cabo mediante este tipo de modelo, permitiendo con ello a los hilos moverse fácilmente entre los diferentes sistemas.
- Modelo de Muchos a Muchos
Combinación de los modelos de Muchos a Uno y Uno a Muchos, con este enfoque se multiplexan varios hilos de nivel de usuario de sobre un número de hilos, el cual es menor o igual a la cantidad de hilos de kernel.
Pipeline
Segmentación (Pipeline) es una técnica de implementación por medio
de la cual se puede traslapar la ejecución de
instrucciones.
- La segmentación no ayuda en la realización de una
única tarea, ayuda en la realización de una carga de
trabajo.
- Se pueden realizar múltiples tareas simultáneamente
utilizando diferentes recursos.
- La velocidad se incrementa si se aumentan el número de
segmentos.
- La razón de segmentación está dada por el segmento
más lento.
- El desbalance en el largo de los segmentos reduce la
velocidad (speedup)
- El tiempo en llenar y vaciar los segmentos reduce la
velocidad.
- Almacén para las dependencias.
En la informática, el pipeline se emplea en
microprocesadores, tarjetas gráficas y software.
Los cálculos que se realizan en el proceso de programación deben sincronizarse
con un reloj para evitar los tramos más recargados que se detectan entre dos
registros.
Etapas en las instrucciones MIPS
•IF: Recuperación de instrucción desde
memoria.
•ID: Lectura de registros mientras se
decodifica la instrucción. Debido al formato regular.
•EX: Ejecución de la operación o cálculo de
la dirección.
•MEM: Acceso a operandos
en memoria de datos.
•WB: Escritura del resultado en los
registros
Aquí están las cuatro etapas en su forma abreviada, que es la más común y la que verás más a menudo:
1. Fetch (Traer)
2. Decode (Descifrar)
3. Execute (Ejecutar)
4. Write (Escribir)
El pipelining no es lo mismo que el paralelismo (aunque, en cierto modo, en el pipeline también hay paralelismo). Ambas técnicas están dirigidas a mejorar el rendimiento (número de instrucciones por unidad de tiempo) incrementando el número de módulos hardware que operan simultáneamente
En el primer caso, el hardware para ejecutar una instrucción no está replicado, simplemente está dividido en varias etapas distintas especializadas, mientras que en las arquitecturas paralelas, el hardware (la CPU) sí está replicado (hay varios procesadores), por lo que varias operaciones pueden ejecutarse de manera completamente simultánea.
El incremento del rendimiento con el pipelining está limitado al máximo número de etapas del procesador, mientras que con el paralelismo, las prestaciones mejoran siempre que se añadan más procesadores .
Problemas del pipe: los riesgos(hazards)
Riesgos estructurales. Una instrucción no puede ejecutar en el ciclo previsto porque el hardware no soporta la combinación de instrucciones dispuestas para ejecutar.
Riesgos de datos. Cuando una instrucción planificada no puede ejecutar en el ciclo previsto porque los datos que necesita aún no están disponibles.
Riesgos de control. Cuando la instrucción planificada no puede ejecutar en el ciclo previsto porque la instrucción recuperada no es la que se necesita.
Memoria Cache
En el sentido general, un caché es un espacio de almacenamiento de velocidad alta donde se guarda una copia de una parte de los datos que se encuentran en un segundo medio de almacenamiento de velocidad más reducida. En caso que nos interesa, el caché de un CPU, se trata de una memoria de muy alta velocidad que por lo general se encuentra integrada en el chip del CPU y guarda una parte de los datos de la memoria RAM para permitir acceder a ellos más rápidamente. La palabra proviene del francés “cache” (pronunciado cash) que significa “escondite”.
En general cuanto mayor es la caché más puertas se requieren para direccionarla por lo que 3enden a ser algo más lentas (incluso a igualdad de tecnología).
Con frecuencia su tamaño está limitado por el espacio disponible en el chip, ya que las caches de primer nivel están integradas.
Tamaños típicos:
Nivel L1: 8-64 KB
Nivel L2: 256 KB – 4 MB
Nivel L3: (menos usual): 2 MB – 36 MB
Las cachés funcionan por lo general bajo la hipótesis de localidad de referencia de varios
tipos, en particular:
• Localidad espacial: si se utiliza un dato en memoria en un instante dado, es muy probable que en los instantes siguientes se utilice algún dato en una dirección cercana.
• Localidad temporal: si se utiliza un dato en memoria en un instante dado, es muy probable que en los instantes siguientes se vuelva a utilizar
Caché de escritura
Además de las políticas detalladas antes, que se refieren a como se comporta el controlador
de caché al momento de producirse una lectura, es necesario considerar también qué ocurre
con las escrituras. Básicamente, frente a una escritura, deben considerarse dos aspectos del funcionamiento del controlador. En primer lugar, frente a una escritura, ¿debe cargarse la línea correspondiente de la caché?
• En una caché write-allocate (asignación en escritura), cuando el CPU desea hacer una escritura a memoria, el controlador de caché carga la línea correspondiente.
• En una caché write-no-allocate, (¿a que no adivinan?), no.
En segunda instancia, si cuando se desea escribir a memoria, la posición involucrada se
encuentra almacenada en caché1 ¿qué hace el controlador?
• En una caché write-through (escritura inmediata), el controlador escribe los cambios tanto en la caché como en la memoria inmediatamente.
• En una caché write-back (escritura demorada), el controlador escribe los cambios a caché pero no realiza la correspondiente escritura en memoria hasta tanto no se desaloje la línea en cuestión.
Políticas de desalojo
Por último, las memorias caché con nivel de asociatividad mayor a uno comparten la característica de que una posición de memoria puede ocupar más de una posición en la memoria caché. Por lo tanto, de encontrarse llenos todos los espacios posibles que puede ocupar una posición de memoria que ingresa a caché, será necesario decidir cual de las alternativas será desalojada. Dicha decisión se toma según una política, entre las que se incluyen:
• LFU (Least Frequently Used, menos frecuentemente usada), que como su nombre lo indica desalojará la línea que haya sido usada con menor frecuencia desde que fue cargada. A su vez, el cálculo de la frecuencia puede hacerse de diversas maneras que dependerán de la implementación del controlador de caché.
• LRU (Least Recently Used, menos recientemente usada) que desalojará la línea que, entre las alternativas, haya sido usada por última vez hace más tiempo.
• FIFO (First In First Out, el primero que entra sale primero).

Las tres funciones de correspondencia que se suelen usar son las siguientes:
Cuando el procesador busca un dato en la memoria se pueden producir dos situaciones:
- Acierto(Hit): Datos están en el nivel superior. La tasa de aciertos(hit rate) define la fracción de los accesos a memoria en los que se han encontrado los datos en el nivel superior.
- Fallo (Miss o fault): Datos no están el nivel superior. Por tanto se debe acceder al inferior para traer el bloque que los contiene.
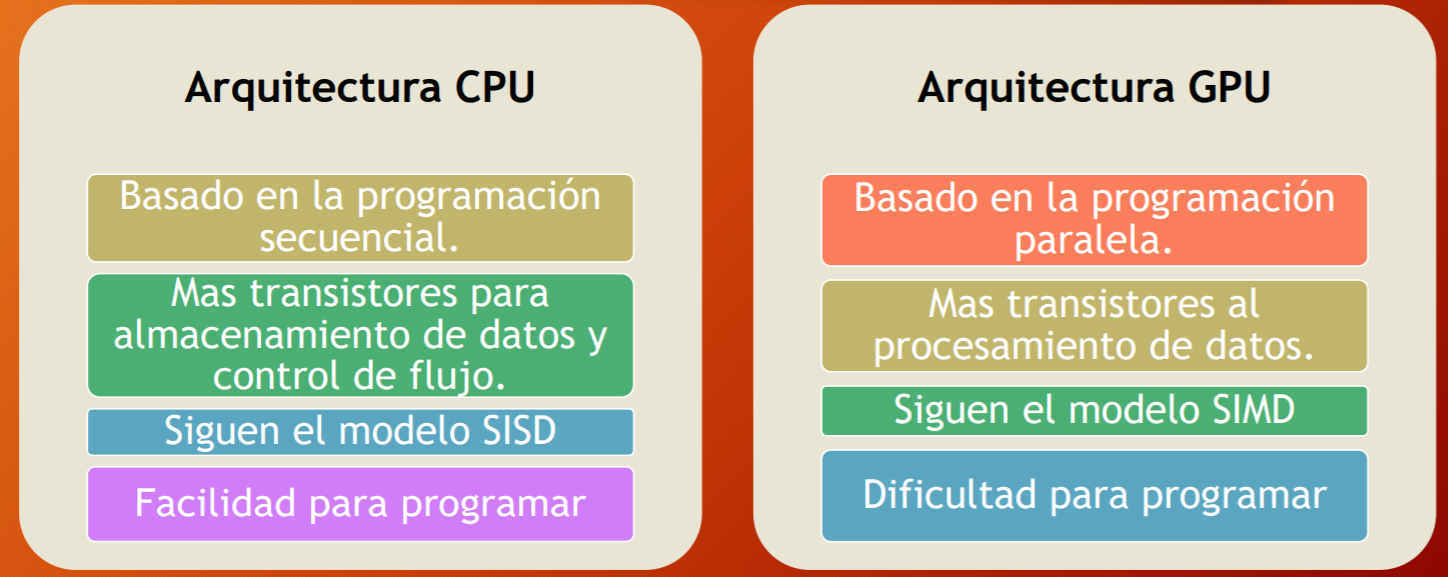
CPU vs GPU
La CPU (unidad de procesamiento central) a menudo se ha llamado el cerebro de la PC. Pero cada vez más, ese cerebro está siendo mejorado por otra parte de la PC: la GPU (unidad de procesamiento de gráficos), que es su alma.
La GPU es una clase en sí misma: va mucho más allá de las funciones básicas del controlador de gráficos y es un dispositivo computacional potente y programable por derecho propio.
Qué es una GPU
Las capacidades avanzadas de la GPU se usaron originalmente principalmente para renderizar juegos en 3D. Pero ahora esas capacidades se aprovechan de manera más amplia para acelerar las cargas de trabajo computacionales en áreas tales como el modelado financiero, la investigación científica de vanguardia y la exploración de petróleo y gas.
"Las GPU están optimizadas para tomar grandes lotes de datos y realizar la misma operación una y otra vez muy rápido, a diferencia de los microprocesadores de PC, que tienden a omitirse por todo el lugar."
Arquitectónicamente, la CPU se compone de pocos núcleos con mucha memoria caché que puede manejar algunos hilos de software a la vez. En contraste, una GPU se compone de cientos de núcleos que pueden manejar miles de subprocesos simultáneamente. La capacidad de una GPU con más de 100 núcleos para procesar miles de subprocesos puede acelerar un poco de software en 100 veces con solo una CPU. Además, la GPU logra esta aceleración a la vez que es más eficiente en términos de energía y de costos que una CPU.


Comparaciones entre CPU y GPU
Desempeño y Rendimiento
Cuando se dice que una computadora es más rápida que otra, ¿qué se quiere decir? El usuario de una computadora individual puede decir que ésta es más rápida cuando ejecuta un programa en menos tiempo, mientras que el director de un centro de cálculo puede decir que una computadora es más rápida cuando completa más tareas en una hora.
El usuario de la computadora está interesado en reducir el tiempo de respuesta – el tiempo transcurrido entre el comienzo y el final de un evento - denominado también tiempo de ejecución o latencia.
Métricas para determinar el rendimiento
El tiempo de ejecución el tiempo es la medida del rendimiento de la computadora: la computadora que realiza la misma cantidad de trabajo en menos tiempo es la más rápida.
El tiempo de ejecución de un programa se mide en segundos por programa. El tiempo se puede definir de formas distintas dependiendo de lo que se quiera contar. La definición más directa de tiempo se denomina tiempo de reloj (wall-clock time), tiempo de respuesta (response time), o tiempo transcurrido (elapsed time). Esta es la latencia para completar una tarea, incluyendo accesos a disco, accesos a memoria, actividades de entrada/salida,gastos del sistema operativo.
Rendimiento del CPU
La mayoría de las computadoras se construyen utilizando un reloj que funciona a una frecuencia constante. Estos eventos discretos de tiempo se denominan pulsos, pulsos de reloj, períodos de reloj, relojes, ciclos o ciclos de reloj.
Los diseñadores de computadoras referencian el tiempo de un período de reloj por su duración (por ejemplo, 10 ns) o por su frecuencia (por ejemplo, 100 MHz). El tiempo de CPU para un programa puede expresarse entonces de dos formas:

Ciclos por Instrucción (CPI)
Además del número de ciclos de reloj para ejecutar un programa, también se puede contar el número de instrucciones ejecutadas - la longitud del camino de instrucciones o el recuento de instrucciones (IC, instruction count). Si se conoce el número de ciclos de reloj y el recuento de instrucciones, es posible calcular el número medio de ciclos de reloj pornstrucción (CPI)
Esta medida del rendimiento del CPU proporciona una nueva percepción en diferentes estilos de repertorios de instrucciones e implementaciones. Al transponer el IC en la fórmula anterior, los ciclos de reloj pueden definirse como ICxCPI. Esto permite utilizar al CPI en la fórmula del tiempo de ejecución:

MIPS y errores de utilización
Hasta el momento se ha visto que la única medida fiable y consistente del rendimiento es el tiempo de ejecución de los programas reales, en esta sección se analizan otras alternativas al tiempo, propuestas como métricas para los programas reales, que presentándose como «items» medidos han conducido, eventualmente, a afirmaciones erróneas o incluso a errores en el diseño de las computadoras. Una de estas alternativas son los MIPS, o millones de instrucciones por segundo. Para un programa dado, los MIPS son sencillamente Recuento de Instrucciones Frecuencia de reloj MIPS = Tiempo de ejecución x 106 = CPI x 106 Algunos encuentran adecuada la fórmula de más a la derecha, ya que la frecuencia de reloj es fija para una máquina y el CPI, habitualmente, es un número pequeño, de forma distinta a la cuenta de instrucciones o al tiempo de ejecución. La relación de los MIPS con el tiempo es:

MFLOPS y errores de utilización
Otra alternativa popular al tiempo de ejecución son los millones de operaciones en punto flotante por segundo, abreviadamente megaFLOPS o MFLOPS, pero siempre pronunciado «megaflops». La fórmula de los MFLOPS es simplemente la definición del acrónimo:

Programas para evaluar el rendimiento
Un usuario de computadoras que ejecuta los mismos programas día tras día sería el candidato perfecto para evaluar una nueva computadora. Para evaluar un nuevo sistema simplemente compararía el tiempo de ejecución de su carga de trabajo habitual (workload) la mezcla de programas y órdenes del sistema operativo que los usuarios ejecutan en una máquina. Sin embargo, pocas veces ocurre esta feliz situación. La mayoría de veces se debe confiar en otros métodos para evaluar las máquinas, y con frecuencia, en otros evaluadores, esperando que estos métodos predigan el rendimiento de la nueva máquina.Niveles de programas utilizados en estas circunstancias, listados a continuación en orden
decreciente de precisión.
1. Programas reales (Real programs). - Aunque el comprador puede no conocer qué fracción de tiempo se emplea en estos programas, sabe que algunos usuarios los ejecutarán para resolver problemas reales. Ejemplos son compiladores de C, software de tratamiento de textos como TeX, y herramientas CAD como Spice. Los programas reales tienen entradas, salidas y opciones que un usuario puede seleccionar cuando está ejecutando el programa.
2. «Núcleos» (Kernels). - Se han hecho algunos intentos para extraer pequeñas piezas claves de programas reales y utilizarlas para evaluar el rendimiento. «Livermore Loops» y «Linpack» son los ejemplos mejor conocidos. De forma distinta a los programas reales, ningún usuario puede correr los programas «núcleo»; únicamente se emplean para evaluar el rendimiento. Los «núcleos» son adecuados para aislar el rendimiento de las características individuales de una máquina para explicar las razones de las diferencias en los rendimientos de programas reales.
3. Benchmarks reducidos (Toy benchmarks). - Los benchmarks reducidos, normalmente, tienen entre 10 y 100 líneas de código y producen un resultado que el usuario conoce antes de ejecutarlos. Programas como la Criba de Eratóstenes, Puzzles, y Ordenamiento Rápido (Quicksort) son populares porque son pequeños, fáciles de introducir y de ejecutar casi en cualquier computadora.
La Ley de Amdahl define la ganancia de rendimiento o aceleración (speedup) que puede lograrse al utilizar una característica particular. Si para una máquina es posible realizar una mejora que, cuando se utilice, aumente su rendimiento. La aceleración está dada por la relación:
Referencias
http://ldc.usb.ve/~yudith/docencia/ci-3825/ClaseThreads.pdf
http://carteleras.webcindario.com/pipeline-intro.pdf
http://www.dacya.ucm.es/hidalgo/arquitectura/pipeline.pdf
https://www.dc.uba.ar/materias/oc1/2010/c2/descargas/apunte-memoria-cache.pdf
http://electro.fisica.unlp.edu.ar/arq/transparencias/ARQII_00-Repaso2.pdf
https://blogs.nvidia.com/blog/2009/12/16/whats-the-difference-between-a-cpu-and-a-gpu/
https://previa.uclm.es/profesorado/licesio/Docencia/ETC/15_MedidasRendimiento_itis.pdf
http://mixteco.utm.mx/~merg/AC/pdfs/Unit_1_Part_2.pdf