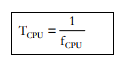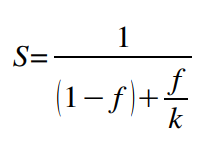Arquitectura de computadoras
Un computador o computadora es una máquina calculadora electrónica rápida
que acepta como entrada información digitalizada, la procesa de acuerdo con
una lista de instrucciones almacenada internamente y produce la información de
salida resultante. A la lista de instrucciones se le conoce como programa y el
medio de almacenamiento interno memoria del computador.
Dentro la comprensión del funcionamiento de las computadoras y de todos los sistemas digitales de la actualidad (celulares, reproductores de música, videojuegos, medidores, controladores, etc.) pasa primero por entender el concepto de circuito lógico. Este concepto está ligado a la lógica simbólica tradicional o lógica Booleana (de George Boole, matemático inglés del siglo XIX). Las entradas y salidas de estos circuitos solo pueden tener dos estados: alto (uno) y bajo (cero).
El dominio de los circuitos binarios en los sistemas digitales es una consecuencia de su simplicidad,que resulta de restringir las señales para asumir solo dos valores posibles. Lo más simple el elemento binario es un conmutador que tiene dos estados en este contexto un estado verdadero 1 o un estado falso 0.
Estos circuitos cuentas con operaciones lógicas básicas reconocidas AND,OR y NOT la principal manera de representación es mediante el uso de tablas de la verdad una ayuda útil para representar información que involucra funciones lógicas.
Representación de Circuitos lógicos:
Circuitos Digitales Combinacionales
Un circuito combinacional es aquel que está formado por funciones lógicas elementales ( AND, OR, NAND, NOR, etc. ), que tiene un determinado número de entradas y salidas, dependiendo los valores que toman las salidas exclusivamente de los que toman las entradas en ese instante. Ejemplo de este tipo de circuitos son : los codificadores, decodificadores, multiplexores, demultiplexores, comparadores, generadores-detectores de paridad, etc.
En este punto se trata el análisis de circuitos combinacionales a nivel de puertas lógicas. La estructura del circuito vendrá dada por su diagrama lógico, cuyos constituyentes serán puertas lógicas cuyo comportamiento lo determina el símbolo que lo representa. Un circuito combinacional se analiza determinando la salida de los elementos lógicos que lo constituyen ( normalmente puertas lógicas ), partiendo de las variables de entrada y avanzando en el sentido de la señal hacia la salida.
Pastes Combinacionales
Partes Cominacionales Utiles
DECODIFICADORES
Un decodificador es un circuito lógico con n entradas y 2 a la n salidas como máximo, tal que para cada combinación de entradas se activa al menos una salida. Si sólo se activa una salida se denomina decodificador completo.
Tanto las entradas como las salidas, principalmente estas últimas, pueden ser:
• ACTIVAS A NIVEL ALTO: la salida activa es 1 y la no activa 0.
• ACTIVAS A NIVEL BAJO: la salida activa es 0 y la no activa 1.
Además el número de entradas de habilitación puede ser de una o más, y
pueden estar activas a nivel alto o bajo.
Podemos encontrar decodificadores de muy diversos “tamaños”:
De 2 a 4 líneas
De 3 a 8 líneas (bin a oct)
De 4 a 16 líneas (bin a hex)
Convertidores de códigos: BCD/decimal y BCD/7-seg
CODIFICADORES
Son los dispositivos MSI que realizan la operación inversa a la realizada por los decodificadores. Generalmente, poseen 2 elevano a la n entradas y n salidas. Cuando solo una de las entradas está activa para cada combinación de salida, sele denomina codificador completo.
MULTIPLEXORES
Multiplexar es pasar información de “muchos” canales o líneas a “pocos”
canales o líneas.Un MULTIPLEXOR (MUX) es un circuito combinacional que selecciona una entrada y la transfiere a la salida. La selección de la entrada, o dato, se realiza según un conjunto de valores de las variables de control.Poseen por tanto, n entradas de selección, para 2 elevado a la n entrada de datos, proporcionando, generalmente, dos salidas: una para el dato directo y otra para el dato negado.
DEMULTIPLEXORES
En realidad no existen como tales, sino que vienen definidos por los
decodificadores/demultiplexores.
La función que debe realizar es la inversa de la que realiza el MUX, o sea,
debemos seleccionar una salida por donde transmitir el dato de la entrada.
Por tanto, el circuito constará de 1 entrada de datos, n entradas de selección de
salida, y 2 elevado a la n
salidas.
Partes Combinacionales Programables
Estos sistemas proporcionan todos los términos posibles que podemos obtener con las variables de entrada. Su estructura es de tipo "AND Fija - OR Programable". Sólo la matriz OR es programable.
PROM
(Programmable Read Only Memory 'Memoria programable de sólo lectura'.
PAL es un sistema combinacional programable universal incompleto,de estructura similar a la de una PLA, de la cual se diferencia en que cada una delas puertas OR están conectadas rígidamente a un conjunto de puertas AND cadauna. En general, si el número de términos producto es n’ y el de salidas m, cadauna de estas últimas irá conectada a n’/m puertas AND.
Una PLA está constituida por una matriz de n’ (n’ < 2n, donde n el númerode entradas) puertas AND y una matriz de puertas OR, ambas programables. Laspuertas AND poseen 2n entradas que se unen a cada variable de entrada a travésde conexiones que pueden ser eliminadas.
CIRCUITOS DIGITALES CON MEMORIA
Circuitos combinacionales con memoria
En los sistemas secuenciales la salida o salidas en un instante de tiempo no solo dependen de los valores de las entradas en ese instante, sino también de los valores que tuvieron en tiempos anteriores.
Circuitos combinacionales sin memoria
Dependen de sus entradas corrientes no tienen historia pasasda ,cantidad finita de memoria
Circuitos secuenciales:
Un latch (Lat Memori Inglet) es un circuito electrónico usado para almacenar información en sistemas lógicos asíncronos. Un latch puede almacenar un bit de información. Los latches se pueden agrupar, algunos de estos grupos tienen nombres especiales, como por ejemplo el 'latch quad' (que puede almacenar cuatro bits) y el 'latch octal' (ocho bits). Los latches pueden ser dispositivos biestables asíncronos que no tienen entrada de reloj y cambian el estado de salida solo en respuesta a datos de entrada, o bien biestables síncronos por nivel, que cuando tienen datos de entrada, cambian el estado de salida sólo si lo permite una entrada de reloj.
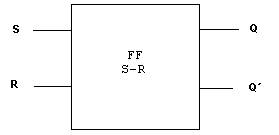
El latch mas simple es el RS y D.
Flip-Flops
Los circuitos secuenciales son aquellos en los cuales su salida depende de la entrada presente y pasada. Dentro de estos circuitos se tienen a los Flip-Flops.
Los Flip-Flops son los dispositivos con memoria mas comúnmente utilizados. Sus características principales son:
Asumen solamente uno de dos posibles estados de salida.
Tienen un par de salidas que son complemento una de la otra.
Tienen una o mas entradas que pueden causar que el estado del Flip-Flop cambie.
Tipos de Flip-Flops
Flip-Flop S-R (Set-Reset)
Flip-Flop T
Flip-Flop J-K
Flip-Flop D
Registros
Represntan un arreglo de flip-flops con entradas de datos individuales y señales de control comun tenemos los siguientes.
Registros de Desplazamiento
Es un registro que ‘registra’ y ‘desplaza’ la información.
Registro de Despalazamiento con carga paralelo
Un registro de este tipo carga todos los bits al mismo tiempo, con lo que no
es necesario esperar muchos pulsos de reloj para obtener la información.
Registro de Desplazamiento Universal
Se trata de un circuito integrado, que dispone de un registro de
desplazamiento, que permite carga serie, carga paralela, desplazamiento a
izquierda y a derecha, mediante el uso de unas señales de control.
Aplicaciones de los registros.
Se utilizan donde se necesiten un almacenamiento temporal de información, por ejemplo, conectados a las salidas de circuitos combinacionales aritméticos para recoger el resultado de una operación, para
almacenar operaciones intermedias o proporcionar información estable a un sistema de representación por displays. Los distintos registros comparten líneas comunes llamadas buses tanto para recoger la información del bus como para volcar la información al bus, pero no todos los registros a la vez, sino uno y después otro. Mientras un registro vuelca su información al bus, otros registros conectados al mismo bus permanecen en estado de alta impedancia.También se suele utilizar para almacenar datos y direcciones en las operaciones de escritura y lectura
de las memorias por parte de los microprocesadores.
Maquinas de estado finito
Una máquina de estado finito M = (S, I, O,f, g, so) consiste de un conjunto finito deestados, un alfabeto finito de entrada I, unalfabeto finito de salida O, una función detransición f que asigna a cada par deestados y entrada un nuevo estado, unafunción de salida g que asigna a cada parde estados y entrada una salida, y unestado inicial so.
Las maquinas de estado finito pueden ser:
*Máquina de Moore: es una máquina de estado que determina sus salidas solamente dependiendo de los estados presentes de la máquina.
*Máquina de Mealy: es una máquina de estado que determina sus salidas dependiendo de los estados presentes de la máquina y de las entradas.
Tipos de de memoria:
SDRAM:Esto significa que se espera una señal de reloj antes de responder a las entradas de control y por lo tanto está sincronizada con el bus de sistema, a diferencia de la DRAM que tiene una interfaz asíncrona lo que significa que responde lo antes posible a los cambios en las entradas de control.
DRAM:Tipo de memoria RAM más usada. Almacena cada bit de datos en un capacitor separado dentro de un circuito integrado. Dado que los capacitores pierden carga, eventualmente la información se desvanece a menos que la carga del capacitor se refresque y cargue periódicamente (períodos cortísimos de refresco).
ROM:Circuito integrado de memoria de solo lectura que almacena instrucciones y datos de forma permanente.
PROM:es una digital donde el valor de cada bit depende del estado de un fusible (o antifusible), que puede ser quemado una sola vez.
EPROM: se programan mediante un dispositivo electrónico, como el Cromemco Bytesaver, que proporciona voltajes superiores a los normalmente utilizados en los circuitos electrónicos. Las celdas que reciben carga se leen entonces como un 0.
Partes secuenciales utiles:
Contador es un circuito secuencial construido a partir de biestable y puertas lógicas capaz de almacenar y contar los impulsos (a menudo relacionados con una señal de reloj), que recibe en la entrada destinada a tal efecto, asimismo también actúa como divisor de frecuencia. Normalmente, el cómputo se realiza en código binario, que con frecuencia será el binario natural o el BCD natural (contador de décadas).
Según la forma en que conmutan los números, podemos hablar de contadores numeradores (todos los números conmutan a la vez, con una señal de reloj común) o asíncronos (el reloj no es común y los números conmutan uno tras otro.
Reloj:Constituye un circuito que emite una señal periódica.
Tecnologías de Sistemas de Computación
Ley de Moore
En 1965 Gordon Moore, co-fundador de Intel, formulo una teoría que se convirtió en ley sobre la velocidad de la evolución de las computadoras (microprocesadores). La ley de Moore nos habla de un crecimiento exponencial: doblar la capacidad de los microprocesadores cada año y medio.
Se estima que esta ley sea valida durante dos décadas mas aproximadamente, cuando no se puedan crear microprocesadores mas pequeños por limitaciones físicas de los materiales usados para crearlos.
GENERACIÓN DE COMPUTADORAS
Tubos de vacío. Grandes,lentos y desprenden mucho calor El uso fundamental fue la realización de aplicaciones en los campos cientifco y militar. Uitlizaban como lenguaje de programación, el lenguaje máquina (o y 1) y como única memorias para conservar la información estaban las tarjetas perforadas y las líneas de demosra de mercurio.
UNIVAC (1950) versión comercial del ENIAC.
Transistores (inventado en 1948). Más rápidos, más pequeños y más fiables. Los campos de aplicación fueron además del científico y militar, el adminsitrativo y de gestión. Comienzan a utilizarse lenguajes de programación evolucionados, como son el ensamblador y lenguajes de alto nivel ( COBOL, ALGOL FORTRAN).
Circuítos integrados (inventados en 1958 por Jack St. Clair Kilby y Robert Noice), también llamados semiconductores.
Circuito integrado encapsula gran cantidad de componentes discretos (resistencias, condensadores, diodos y transistores), conformando uno o varios circuitos en una pastilla de silicona o plástico.
Microprocesador del mundo (1971). Uso de memorias electrónicas.Ordenadores conectados a redes. Uso del disquete como uniDad de almacenamiento. Aparecen gran cantidad de lenguAjes de programación de todo tipo y las redes de transmisión de datos parA la interconexión de computadoras.
De los componentes a las aplicaciones es un proceso que pasa por diferentes etapas de diseño y diseñadores algunas de ellas son:
Diseñar aplicaciones con el Diseñador de aplicaciones. El Diseñador de aplicaciones proporciona una superficie para diseñar, configurar y conectar aplicaciones que que proporcionan o utilizan servicios. Con estas definiciones de aplicación, puede crear sistemas de aplicación y evaluar su implementación.
Diseñador de sistemas es el que de define la arquitectura de hardware y software, componentes, módulos y datos de un sistema de cómputo, a efectos de satisfacer ciertos requerimientos. Es la etapa posterior al análisis de sistemas
Diseñador de computadoras conocimiento a nivel logico para entender sumadores de archivos de registro y estar informado sobre conflictos en el area de diseño de sistemas.
Diseñador lógico es el que se encarga de construir un esquema logico con patrones los diferentes patrones.
Diseñador de circuitos es la parte de la electrónica que estudia distintas metodologías con el fin de desarrollar un circuito electrónico.
Sistemas de cómputos y sus partes
Sistemas de computo personales, servidores, estación de trabajo, super computadoras y las diferentes medio de entrada y salida como ser mouse, teclado, monitor, escaner etc...
Sistema de software y sus aplicaciones
La palabra software se refiere a las instrucciones que se incorporan a un sistema informático para que este lleve a cabo una determinada función. Partiendo de esta sencilla definición, el campo que se esconde detrás es inmenso, porque engloba desde pequeñas aplicaciones para llevar a cabo tareas muy específicas, a archivos conocidos sistemas operativos con capacidad para realizar miles de funciones.
Rendimiento de Computadoras
Se define rendimiento de un sistema como la capacidad que tiene dicho sistema para realizar un trabajo en un determinado tiempo. Es inversamente proporcional al tiempo, es decir, cuanto mayor sea el tiempo que necesite, menor será el rendimiento. Los computadores ejecutan las instrucciones que componen los programas, por lo tanto el rendimiento de un computador está relacionado con el tiempo que tarda en ejecutar losprogramas. De esto se deduce que el tiempo es la medida del rendimiento de un computador.
El rendimiento del procesador depende de los siguientes parámetros:
1. Frecuencia de la CPU (fCPU) : es el número de ciclos por segundo al que trabaja el procesador o CPU. No confundir la frecuencia de la CPU con la frecuencia del sistema, el bus delsistema trabaja a menor frecuencia que la CPU.
2. Periodo de la CPU (TCPU) : es el tiempo que dura un ciclo y es la inversa de la frecuenciade la CPU.
3. Ciclos por instrucción (CPI) : las instrucciones se descomponen en micro instrucciones,que son operaciones básicas que se hacen en un ciclo de reloj. En un programa se llama CPI al promedio de micro instrucciones que tienen las instrucciones del programa, es decir, los ciclos de reloj que se tarda de media en ejecutar una instrucción.
4. Número de instrucciones del programa : cuantas más instrucciones haya en el
programa más tiempo se tarda en ejecutarlo luego baja el rendimiento. El que tengamos un número
reducido de instrucciones dependerá del programador y de que dispongamos de un buen
compilador.
5. Multitarea :hace referencia a la capacidad que tiene un computador de atender simultáneamente varias tareas. Como anteriormente hemos comentado, el rendimiento de un procesador para un programa concreto es un factor inversamente proporcional al tiempo que tarda en ejecutar dichoprograma.
El tiempo de programa depende a su vez del número de instrucciones del programa y del tiempo que se tarda en ejecutar cada instrucción.
Principios de Diseño.
1. Diseñando con la Ley de Moore en mente.
Indica que los recursos de circuitos integrados duplican cada 18-24 meses. Los recursos disponibles por chip pueden duplicarse o cuadruplicarse fácilmente entre el comienzo y la conclusión del proyecto.
2. Use la abstracción para simplificar el diseño.
Una de las principales técnicas de productividad para el hardware y el hardware es utilizar abstracciones para representar el diseño en diferentes niveles de representación; Los detalles de nivel inferior están ocultos de un modelo más simple en niveles más altos.
3. Haga que el caso común sea rápido.
Hacer que el caso común sea rápido tenderá a mejorar el rendimiento mejor que optimizando el caso raro. Irónicamente, el caso común es más sencillo que el caso raro y por lo tanto es más fácil de mejorar.
4. Desempeño vía paralelismo.
Los arquitectos de computadoras tienen diseños más rendimiento realizando operaciones en paralelo.
5. Desempeño vía Pipelining.
Un patrón particular de paralelismo es tan frecuente en la arquitectura computacional que
Merece su propio nombre: pipelining.
6. Desempeño vía predicción
En algunos casos puede ser más rápido en promedio para adivinar y empezar a trabajar en lugar de esperar hasta que sepa con seguridad, suponiendo que el mecanismo para recuperarse de una mala predicción no es demasiado caro y su predicción es relativamente precisa.
7. Jerarquía de memorias.
La memoria más rápida, más pequeña y más cara por bit en la parte superior de la jerarquía
Y el más lento, más grande y más barato por bit en la parte inferior. La forma indica velocidad, costo y tamaño: cuanto más cerca de la parte superior, más rápido y más caro por bit la memoria; Cuanto más ancha sea la base de la capa, mayor será la memoria.
8. Dependencia vía redundancia.
Los ordenadores no sólo necesitan ser rápidos; necesitan ser confiables. Dado que cualquier dispositivo puede fallar, hacemos que los sistemas sean fiables incluyendo componentes redundantes que puede asumir el control cuando ocurre un fallo y para ayudar a detectar fallas.
Costo, Rendimiento y costo/rendimiento
Un atributo clave de un sistema de cómputo es su costo. En cualquier año específico, probablemente se pueda diseñar y construir una computadora que sea más rápida que la más rápida de las computadoras actuales disponibles en el mercado. Sin embargo, el costo podría ser tan inalcanzable que quizá esta última máquina nunca se construya o se fabrique en cantidades muy pequeñas por agencias que estén interesadas en avanzar el estado del arte y no les importe gastar una cantidad exorbitante para lograr esa meta. Por ende, la máquina de mayor rendimiento que sea tecnológicamente factible puede nunca materializarse porque es ineficaz en costo (tiene una razón costo/rendimiento inaceptable debido a su alto costo).
Sería simplista igualar el costo de una computadora con su precio de compra. En vez de ello, se debería intentar evaluar su costo de ciclo de vida, que incluye actualizaciones, mantenimiento, uso y otros costos recurrentes. Observe que una computadora que se compra por dos mil dólares tiene diferentes costos. Puede haberle costado 1500 dólares al fabricante (por componentes de hardware, licencias de software, mano de obra, embarque, publicidad), y los 500 dólares restantes cubran comisiones de ventas y rentabilidad. En este contexto, podría llegar a costar cuatro mil dólares durante su tiempo de vida una vez agregado servicio, seguro, software adicional, actualizaciones de hardware, etcétera.
La formula para el rendimiento es la siguiente:
1/ tiempo de ejecución
Mejorar el rendimiento Ley de Amdhal: Siendo T el tiempo de ejecución de una tarea, y f la fracción de ese tiempo que puede acelerarse un factor k, la aceleración obtenida será:
Medición del rendimiento contra el modelado
Una prueba de rendimiento o comparativa (en inglés benchmark) es una técnica utilizada para medir el rendimiento de un sistema o uno de sus componentes. Más formalmente puede entenderse que una prueba de rendimiento es el resultado de la ejecución de un programa informático o un conjunto de programas en una máquina, con el objetivo de estimar el rendimiento de un elemento concreto, y poder comparar los resultados con máquinas similares. En el ámbito de las computadoras, una prueba de rendimiento podría ser realizada en cualquiera de sus componentes, ya sea la CPU, RAM, tarjeta gráfica, etc. También puede estar dirigida específicamente a una función dentro de un componente, como la unidad de coma flotante de la CPU, o incluso a otros programas.
INSTRUCCIONES Y DIRECCIONAMIENTO
La vision abstracta del hardware de computadora es su arquitectura de conjunto de instrucciones. Es necesario aprender esta interfaz para ser capaz de indicar a la computadora a realizar tareas computacionales de interés.
Una de los conjuntos de instrucciones que utilizaremos es el MIPS (Machine without Interlocked Pipelined Stages)
Arquitectura diseñada por Hennessey, en 1980,guiada por los siguientes principios:
– La simplicidad favorece la regularidad
– Más pequeño es más rápido (menos es mas)
– Hacer rápido el caso común
Objetivos de diseño: maximizar rendimiento y reducir costos usado por: NEC, Nintendo, Silicon Graphics, Sony.
MIPS es un conjunto de instrucciones load/store (carga/almacenamiento), ello significa que los elementos de datos se deben copiar o cargar (load) en registros antes de procesarlos; los resultados de operación también van hacia registros y se deben copiar explícitamente de vuelta a la memoria a través de operaciones store (almacenamiento) separadas.
Organización MIPS
Unidad Aritmética y Lógica (ALU) Unidad Aritmética entera, operaciones demultiplicación y división. Unidad punto flotante (FPU). Coprocesador dedicado al manejo de memoria caché y virtual.
Memoria
Se denomina palabra (word) al contenido de una celda de memoria.MIPS posee palabras de 32 bits. Las direcciones de memoria correspondes adatos de 8 bits (byte). 4 bytes en una palabra.Para acceder a una palabra se leen 4 bytes.
Dos formas de numerar los bytes contenidos en una palabra:Big endian (IBM, Motorola, MIPS)
Dos formas de numerar los bytes contenidos
en una palabra: Little endian (Intel, Dec)
Formato de Instrucciones
Formato de Instrucciones MIPS Formato R para operaciones.
Tres registros, dos para especificar las fuentes de datos y ellugar para almacenar el resultado.
Instrucciones de corrimiento utilizan el campo Shamnt (Shift Amount), especifica el número de posiciones de bits que sedesplazará uno de los operandos.
Un campo para expandir el código de operación.
Op: Operacion
Rs: Primer registro operando fuente
Rt :Segundo registro opeando fuente
Rd:Registro operando distinto donde se almacena el resultado de la operacion.
Shamnt:Tamaño del desplazamiento.
Funct:Funcion este campo selecciona la variante especifica de la operacion del campo op y aveces se le denomina codigo funcion.
Formato I para inmediatas, transferencias y
bifurcaciones. Se emplean 16 bits, para programar un valor constante.Basta un registro de operando y otro para depositar elresultado.Las operaciones lógicas se extienden los 16 bits a 32 conceros en la parte más significativa. Las operaciones aritméticas se extienden con signo.
Formato J para saltos
Posee un campo de 26 bits que se emplea para generar la dirección efectiva de salto.
Formato Load -Store
Tipos de instrucciones de MIPS
El conjunto de instrucciones que especificamos permite realizar operaciones de carga y almacenamiento desde y hacia memoria tendrá capacidad de desarrollar programas aritméticos y lógicos y ofrecerá la posibilidad de controlare el flujo de la ejecución del programa mediante instrucciones de comparación y salto tanto condicionales como incondicionales en resumidas cuentas tendremos:
Instrucciones Aritméticas.
Instrucciones Lógicas.
Instrucciones de carga.
Instrucciones de comparación.
Instrucciones de salto condicional.
Instrucciones de salto incondicional.
Modos de direccionamiento
Contar con diferentes formatos de instrucciones, implica contar con diferentes formas de obtener los operandos de las instrucciones. Por lo general a estas múltiples formas se les conoce como modos de direccionamiento. Los modos de direccionamiento en MIPS son:
Direccionamiento por registro, donde los operandos son registros. Los datos a operar están contenidos en 2 registros de 32 bits y el resultado será colocado en otro registro, del mismo tamaño.
Direccionamiento base o desplazamiento, donde uno de los operandos está en una localidad de memoria cuya dirección es la suma de un registro y una constante que forma parte de la misma instrucción.
Direccionamiento inmediato; donde uno de los operandos es una constante que está en la misma instrucción.
Direccionamiento relativo al PC, donde se forma una dirección sumando una constante, que está en la instrucción, con el registro PC (Program Counter). El resultado de la suma corresponde a la dirección destino si un brinco condicional se va a realizar.
Direccionamiento pseudo directo, donde la dirección destino de un salto corresponde a la concatenación de 26 bits que están en la misma instrucción con los bits mas significativos del PC.
Ejemplos MIPS:
código C: A = B + C
código MIPS: add $s0, $s1, $s2
código C: A = B + C + D;
E = F - A;
código MIPS: add $t0, $s1, $s2
add $s0, $t0, $s3
sub $s4, $s5, $s0
codigo estructura if
codigo estructura for
Ejemplos de MIPS elaborados en clase con QTSPIM
Ejercicio 1
data
.text
.globl main
main:
li $t0,1
li $t1,3
li $t2,2
bne $t0,$t1,continuar
add $t2, $t2, 1
continuar: add $t3, $t0, $t1
li $v0,10
syscall
Ejercicio 2
.data
.text
.globl main
main:
li $t0,2
li $t1,2
li $t2,3
bne $t0,$t1,continuar
add $t2, $t2, 1
continuar: add $t2, $t0, $t1
li $v0,10
Ejercicio 3
.data
.text
.globl main
main:
li $t0,1
li $t1,10
li $t2,5
while:
slt $t3, $t0,$t1
beq $t3,$zero,end
add $t0, $t0, 1
add $t2, $t2, 1
j while
end:
li $v0,10
syscall
Ejercicio 4
.data
.text
.globl main
main:
li $t0,1
li $t1,5
li $t2,2
slt $t3, $t0,$t1
beq $t3,$zero,else1
add $t5, $t0,$t0
sub $t1, $t0,$t5
else1:
slt $t4, $t1,$t0
beq $t4,$zero,else2
add $t6, $t1, $t1
sub $t0, $t1,$t5
else2:
add $t2, $t2,1
end:
li $v0,10
syscall
Ejercicio 5
.data
.text
.globl main
main:
li $t0,2
li $t1,10
do:
slt $t3, $t0,$t1
beq $t3,$zero,end
add $t1, $t1, 1
add $t0, $t0, 1
add $t0, $t0, 1
j do
end:
li $v0,10
syscall
Referencias
http://www.aliat.org.mx/BibliotecasDigitales/sistemas/Arquitectura_computadoras_I.pdf
http://paginas.fisica.uson.mx/horacio.munguia/aula_virtual/Cursos/Instrumentacion%20I/Temario/Circuitos%20Logicos.htm
http://paginas.fisica.uson.mx/horacio.munguia/aula_virtual/Cursos/Instrumentacion%20I/Documentos/Intro_Circuitos_Logicos.pdf
http://www.profesormolina.com.ar/electronica/componentes/int/sist_comb.htm
http://www.uhu.es/rafael.lopezahumada/descargas/tema5_fund_0405.pdf
http://www.uhu.es/rafael.lopezahumada/descargas/tema9_fund_0506.pdf
http://cidecame.uaeh.edu.mx/lcc/mapa/PROYECTO/libro16/43_latches.html
http://www.uhu.es/rafael.lopezahumada/Cursos_anteriores/fund01_02/tema8.pdf
http://www.esi.uclm.es/www/isanchez/teco0910/profesor/tema8.pdf
http://www.profesores.frc.utn.edu.ar/electronica/tecnicasdigitalesi/pub/file/AportesDelCudar/Maquinas%20de%20Estado%20MC%20V5.pdf
http://bv.ujcm.edu.pe/links/cur_sistemas/ArqComputadoras-02.pdf
http://www.dacya.ucm.es/lanchares/documentos/2.9.5%20Apuntes%20de%20Estructura%20de%20Computadores.pdf
https://www.infor.uva.es/~bastida/OC/TRABAJO2_MIPS.pdf
http://profesores.elo.utfsm.cl/~tarredondo/info/comp-architecture/paralelo2/C03_MIPS.pdf